Le point de départ
En lisant – on a les occupations qu’on peut – le livre de préparation de la certification CISSP (# (ISC)2 CISSP Certified Information Systems Security Professional Official Study Guide, 9th Edition – ISBN-10: 1119786231), je suis tombé sur une page concernant le threat modelling.
L’idée est de représenter visuellement un certain nombre de composants d’une solution pour faciliter l’identification des menaces. Exemple :
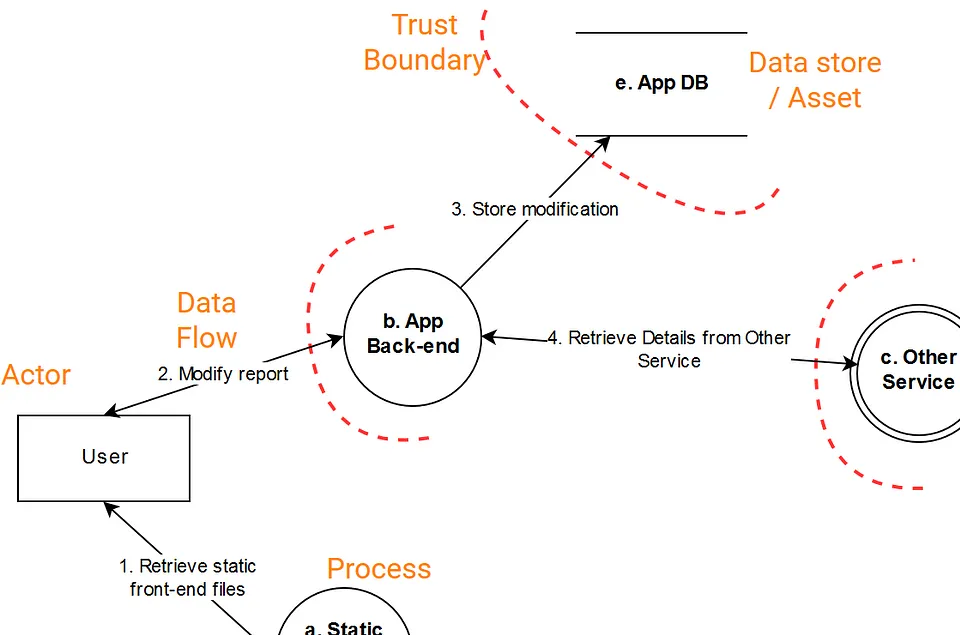
Il s’agit d’une forme de représentation graphique que je n’avais jamais croisée dans le monde professionnel. Y sont notamment indiqués :
- les briques de la solution,
- les interaction entre ces briques : sous forme de requête/réponse systématiquement, je n’en ai pas trouvé la raison
- les « security boundaries »
- les fonctions exécutés avec des privilèges élevés.
Je n’ai pas trouvé de formalisme bien défini pour ce type de visualisation et me suis demandé si Archimate pouvait répondre à ce type de besoin en apportant un peu plus de « cadre » à la représentation.
Cet article présuppose que vous connaissez Archimate ainsi que le logiciel Archi . Un autre logiciel peut sans aucun doute aboutir au même résultat visuellement mais la deuxième partie de l’article fait appel au plugin jArchi spécifique à Archi.
Le schéma
Première étape, une proposition de mapping entre les concepts utilisés pour ce threat modelling et les concepts Archimate :
| Eléments du threat model | Concept Archimate |
|---|---|
| briques de la solution étudiée | Tout élément pertinent du métamodèle « core » |
| interactions entre les briques | « flow-relationship » qui représente à la fois la requête et la réponse |
| security boundaries | voir plus bas |
| Fonctions privilégiées | application-function |
| Threat | assessment (voir How to Model Enterprise Risk Management and Security with the ArchiMate® Language Nov 2019 TOGAF) |
La difficulté principale est, à mon sens, la modélisation des « frontières », Archimate n’ayant pas de concept de « limite ». Plusieurs solutions sont envisageables
-
faire passer le flux « au travers/par-dessus » : visuellement satisfaisant mais cela reste une convention graphique et ne se retrouve pas dans le modèle.
-
la frontière comme concept : visuellement satisfaisant mais on scinde le flux en 2 sous-flux, ce qui alourdit le modèle et complique l’analyse
-
un attribut ou une spécialisation du flux : on peut par exemple ajouter un attribut « secBoundaries = zone 1 | zone 2 » et/ou une spécialisation. Visuellement, ce n’est pas très parlant, et nécessite un code couleur pour bien le mettre en évidence. C’est facile à analyser mais peu pratique à mettre à jour : le jour ou « zone 2 » est renommé il faut penser à mettre à jour les propriétés des flux concernés
-
associer un concept au flux : en liant un concept de type « technology-interface » au flux, on obtient quelque chose visuellement parlant, facile à analyser dans le modèle et à mettre à jour.
-
utiliser des concepts déjà modélisés : ici les différentes briques applicatives sont liées à des locations. Visuellement, cela charge un peu le schéma mais on voit immédiatement les flux qui passent d’une « location » à l’autre. Bien entendu cela implique que les « locations » soient correctement modélisées pour représenter les zones logiques d’un SI (et non uniquement des sites physiques par exemple).
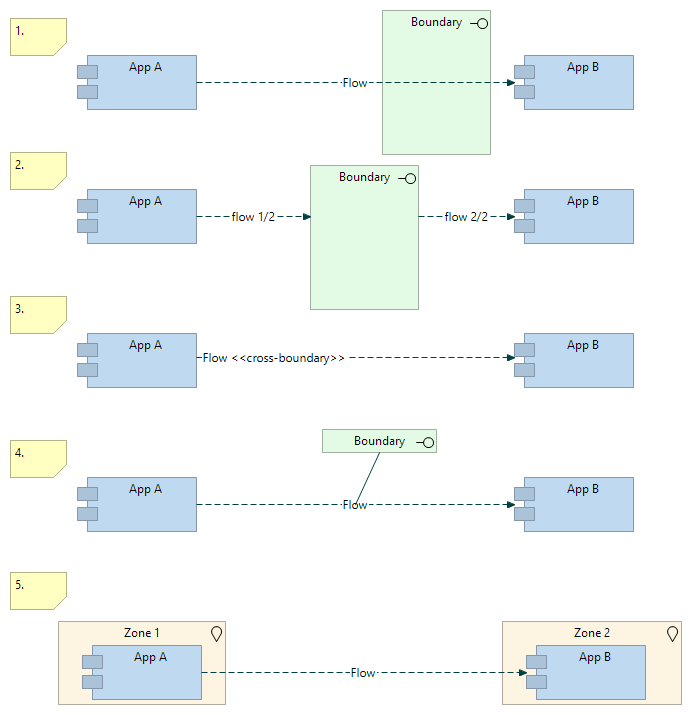
La dernière approche a ma préférence car elle évite d’introduire un nouveau concept pour représenter la « boundary » tout en permettant de réutiliser des concepts qui ont probablement déjà été introduits par ailleurs dans le modèle.
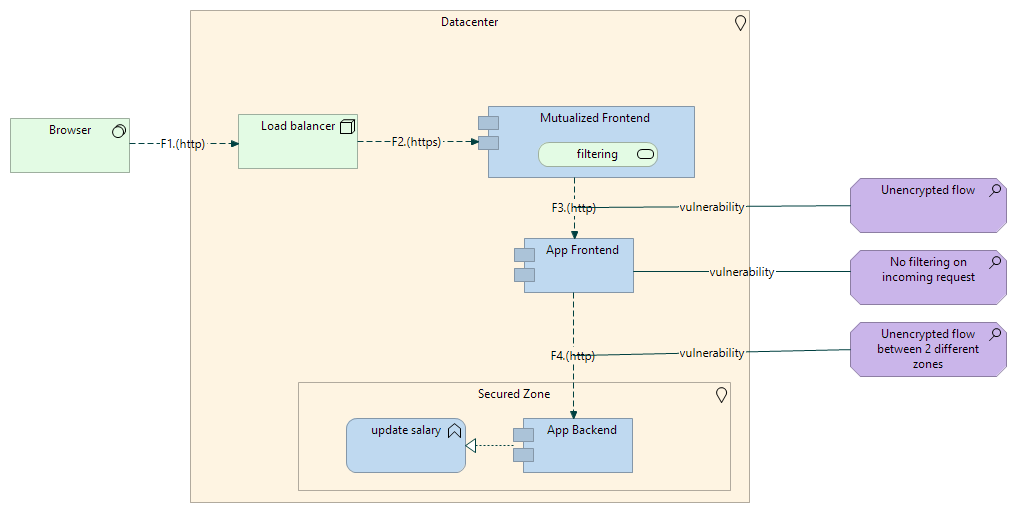
Voilà un exemple basique pour une application web avec load balancer, serveurs frontends mutualisés à la maille de l’entreprise, puis frontends et backends dédiés à chaque application. Les backends sont dans une zone sécurisé, tout le reste est dans une zone réseau « à plat ». On a donc 2 « boundaries » :
- entre le browser et le datacenter,
- entre la zone par défaut du datacenter et la zone dite sécurisée.
Enfin, on identifie 3 vulnérabilités (en violet), nous y reviendrons dans le § suivant : 2 sont associées à des flux non chiffrés, 1 à l’absence de filtrage sur un frontend.
Pour aller plus loin
Nous avons maintenant produit un visuel, c’est bien, cela permet de communiquer, de clarifier les concepts. Tout l’intérêt de modéliser n’est pas juste de produire un beau schéma, mais de progressivement bâtir un modèle qu’on pourra ensuite valoriser par des analyses, des requêtes. Mon objectif est ici, une fois une vulnérabilité modélisée, de « scanner » le reste du modèle afin de détecter tous les autres cas où cette vulnérabilité se rencontre.
Sur l’exemple, ci-dessus, on modélise 3 vulnérabilités :
- flux http non chiffré,
- flux http non chiffré entre 2 zones différentes (ce qui correspond à un flux traversant les fameuses boundaries abordées au début de l’article),
- Frontend non associé à du filtrage : on suppose ici que cela induit la possibilité qu’un attaquant se connecte directement auprès du frontend de l’application sans passer par les briques précédentes qui peuvent porter des services de sécurité.,
Pour cela, nous avons besoin de créer des règles. Elles vont être implémentées via une propriété de la vulnérabilité, ici notée « check_rule » :

La première vulnérabilité « Unencrypted flow » se code :
o.name.indexOf("(http)")>-1
Se traduit par, « il y a vulnérabilité si le nom du flux indique que le protocole est (http) ».
La vulnérabilité « Unencrypted flow between 2 different zones » peut se coder de la façon suivante :
((o.name.toLowerCase().indexOf("(http)")>-1) && (!compareFirstAncestors(o.source,o.target,"location")))
En bon français, cela se lit : on a une vulnérabilité si le flux est indiqué comme (http) ET que la source et la destination du flux sont situés dans des « locations » différentes.
La méthode compareFirstAncestors n’existe pas dans le SDK de jArchi, c’est une méthode que j’ai conçue pour l’exemple et qui compare le premier « parent » de type « location » contenant chacun des 2 concepts passés en paramètre de la méthode. Elle retourne true si c’est le même concept.
Enfin, la vulnérabilité « No filtering on incoming request » décrite de manière ultra-simplifiée par :
(o.name.indexOf("Frontend")>-1) && (!isRelatedTo(o, "filtering","association-relationship"))
Traduction : il y a vulnérabilité si le composant contient le terme « Frontend » et n’est pas lié à un bloc nommé « filtering ».
De même que « compareFirstAncestors », la méthode « isRelatedTo » a été créée spécifiquement pour mon besoin.
Reste à rédiger ensuite le script qui va vérifier ces règles sur l’ensemble du modèle.
- Le script doit itérer sur l’ensemble des concepts « assessment » du modèle.
- Si « l’assessment » possède une propriété check_rule, on évalue la valeur de cette propriété.
- Si elle est vraie, on créé une relation entre « l’assessment » et l’objet ne respectant pas la règle.
Le code suivant implémente ceci de manière très basique, il mérite un peu de travail pour être pleinement opérationnel :
$("assessment").each(function (as) {
let rule = null;
if (as.prop("check_rule") !== undefined) {
rule = as.prop("check_rule");
let assessedElement = "";
//get the type of the concept associated with the assessment (suppose that an assessment is always associated with this type of concept across models)
$(as).rels("association-relationship").ends().each(function (element) {
if (element.type !== "assessment") {
assessedElement = element.type;
return;
}
})
//check for all concepts of this type in the model
$(assessedElement).each(function (o) {
//if rule evaluation is true, create a vulnerabilty association between assessment and object
if (eval(rule)) {
if ($(as).rels("association-relationship").ends(o.type).filter("#" + o.id).size() === 0) {
model.createRelationship("association-relationship", "vulnerability", as, o)
} else {
//do nothing at the moment
}
} else {
//delete relationship
$("association-relationship").each(function (rel) {
if ((rel.source.id === as.id)&& (rel.target.id===o.id) && rel.name==="vulnerability") {
rel.delete();
}
});
}
})
}
});
Notez la ligne « eval(rule) » qui comme son nom l’indique évalue (cad exécute) la ligne de code indiquée par la propriété « check_rule » de l’assessment.
Après avoir passé le script (et, pour les raisons du test modifiés le protocole du flux browser > load balancer en http), 2 nouvelles associations sont apparues dans le modèle (mais pas dans la vue, on pourrait toutefois facilement les faire ajouter dans le script) :

Il y a donc nécessité de faire un peu de code et, surtout, de fournir un effort de formalisation des vulnérabilités. En contrepartie, cet exemple permet de discerner les apports d’un modèle, apports qui vont bien au-delà de simple représentation visuelle.
Conclusion
Ainsi, au-delà d’une « simple » représentation graphique via Archimate (ce qui est déjà beaucoup, entendons-nous bien), on peut utiliser la puissance du modèle pour capitaliser les vulnérabilités détectées sur une solution et rechercher leur occurrence dans les autres solutions modélisées.